The internet is full of discussions about the new tax law that went into effect for 2018. In particular, people seem to really dislike the new $10,000 cap on State, Local, and Property Tax deductions. The thinking is that this amounts to “double taxation” on anything over the cap, and that’s just not right.
But we should put this in context of the full changes to the tax code. The standard deduction was also increased substantially and, in general, marginal tax rates went down.
So let’s cut through the hyperbole and run some numbers. How does this actually affect your life? In particular, how much Federal tax do you have to pay in 2018 relative to what you paid in 2017?
An email from my friend’s father on this topic stated:
[I’m concerned about] the impact on double taxation in the high income states and locations that have higher real estate taxes. I have a friend whose income is probably around $200,000 per year, so even assuming that his deductions take him to a reasonable AGI – he probably has around $2500 in state income taxes and his home has $14,000 in Real Estate Taxes (County, Local & School) – so under the new tax law he will pay federal taxes on $6,500 of this $16,500 in SALT [State and Local Taxes].
We’ll use this friend as an example here. We’ll call him Bob. Since Bob owns a home with $14k in property taxes, I’m assuming he’s married and has kids in a good school district. Because he only mentions Bob’s income, I’ll assume that Bob’s wife is a stay-at-home mom. So that $200k is their combined household income.
Continued…
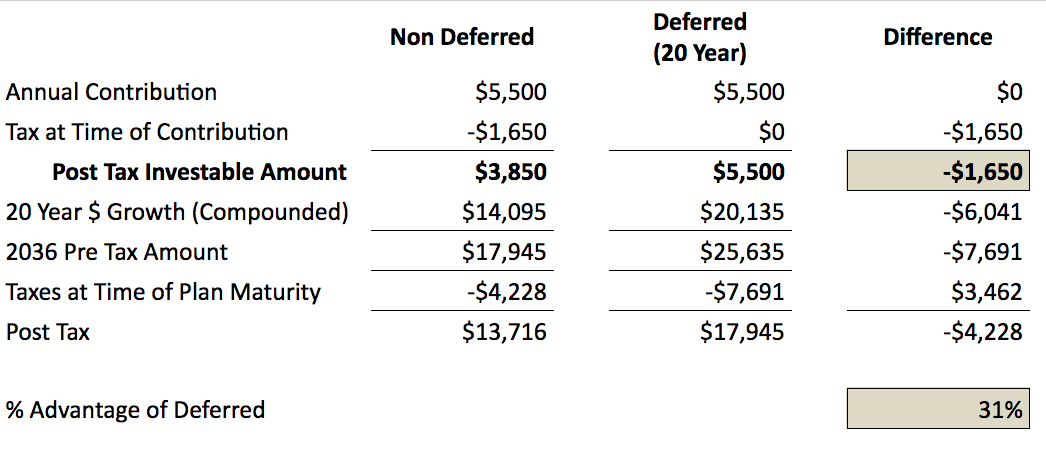

The New 2018 Tax Law and You
The internet is full of discussions about the new tax law that went into effect for 2018. In particular, people seem to really dislike the new $10,000 cap on State, Local, and Property Tax deductions. The thinking is that this amounts to “double taxation” on anything over the cap, and that’s just not right.
But we should put this in context of the full changes to the tax code. The standard deduction was also increased substantially and, in general, marginal tax rates went down.
So let’s cut through the hyperbole and run some numbers. How does this actually affect your life? In particular, how much Federal tax do you have to pay in 2018 relative to what you paid in 2017?
An email from my friend’s father on this topic stated:
We’ll use this friend as an example here. We’ll call him Bob. Since Bob owns a home with $14k in property taxes, I’m assuming he’s married and has kids in a good school district. Because he only mentions Bob’s income, I’ll assume that Bob’s wife is a stay-at-home mom. So that $200k is their combined household income.
Continued…
Posted in Commentary, Personal Finance.
No comments
By codyaray – January 18, 2018